z/OS Mainframe
Du har sikkert aldrig hørt om z/OS. Det skal du ikke være ked af. Du tænker jo heller ikke på, om dit el kommer fra vindmøller eller et kraftværk. Det er der bare, og det er der altid. z/OS er operativsystemet, der leverer din daglige IT, ligesom din el-leverandør sørger for strøm til din hårtørrer. Hvad Watson, der vandt Jeopardy, er for videnskaben, er z/OS for admistrationen i private og offentlige selskaber. IBM har et bogstav for hver type computer, 'x' for Windows og Linux, 'p' for Unix, 'i' for midrange computer, tidligere kendt som AS/400 og 'z' for z/OS. Mange har spekuleret på, hvad 'z' står. 'z' er det sidste bogstav i det engelske alfabet, så der kommer ikke noget efter og større. Nogen mener, at det står for "zero downtime", da z/OS er kendt for at være utrolig stabil. Lige nu er det nok at vide, at z/OS er "state-of-the-art" for operativsystemer.Der er z/OS bag alle dine banktransaktioner; Netbanker, MobilePay, Dankort og MasterCard. Næsten alle forsikringsselskaber, offentlige institutioner, som SKAT, og andre store selskaber, bruger z/OS som fundamentet for deres IT-infrastruktur. Din løn eller SU bliver beregnet og udbetalt med z/OS. "Jamen, hvorfor har jeg så ikke hørt om z/OS", vil du nok spørge. Det kan muligvis være fordi, du bruger din egen PC's operativsystem til at kommunikere med z/OS. Næsten ingen kommunikerer direkte med z/OS. Det går altid gennem andre og mindre operativsystemer. Det kan også være fordi, ingen private kører z/OS, så det er ikke interessant at skrive om i aviser og magasiner. Du kan imidlertid være sikker på, at næsten alle IT-chefer kender z/OS, for enten har de selv en, lejet sig ind på en eller også overvejer de at bruge en. z/OS kører på specielt bygget hardware kaldet System z, som, uden sammenligning, er den kraftigste, sikreste og mest stabile computer til administrative systemer.
Hvad er det så for en computer, vi snakker om? Den blev kaldt for "mainframe" og blev opfundet i 1964, altså for 50 år siden. Den fik verdens første operativsystem. Inden da, blev alle programmer skrevet helt fra bunden, men IBM kunne se, at mange ting var fælles for alle programmer, f.eks. at skrive og læse på tape og disk. IBM har siden ofret milliarder af dollars på at følge med kundernes krav. I senere artikler vil vi gennemgå udviklingen frem til i dag og gennemgå implementeringen af de forskellige krav, der er til et operativsystem, der er verdensledende, og samtidig har beskyttet kundernes investeringer i egne programmer. Der kører endda en Unix under z/OS, så man kan flytte sine Unix-programmer, der måske er skrevet i c/c++, til z/OS. z/OS er også en Java-server med en specialudviklet Java Virtual Machine, JVM.
Jeg vil slutte med at citere en god ven fra IBMs z/OS-laboratorie nord for New York: "The mainframe runs the western civilization".

If you are a z/OS-geek you might enjoy this blog about assembler language. The topics are things I found rather difficult to understand when I had to learn assembler for the first time.
To verdener i IT fødes
Verdens første generelle operativsystem blev opfundet i 1964 af IBM og hed System 360. Arkitekturen udsprang af hulkort som inputmedie. Der kom efterfølgende mange andre operativsystemer, hvor de mest kendte er UNIX og Windows. Begge er udsprunget fra hulstrimmel som inputmedie. Selvom det er mellem 40 og 50 år siden, har det stor indvirkning på disse to arkitekturer, den dag i dag.Hulkort
Hulkortene var papkort, som kunne indeholde 80 kolonner med hver op til 9 huller. Hver kolonne repræsenterede en karakter i tegnsættet EBCDIC, et 8-bit tegnsæt. Hvis ikke man brugte alle 80 karakterer, var pladsen spildt. Til gengæld kunne man sortere hulkortene i f.eks. kundenummerorden. Det var praktisk, for så kunne man sammenkøre kundekartoteket med fakturalinjer og skrive fakturaer ud. I mainframen flyttede man kundekartoteket ind på disk eller, hvis den var meget stor, på tape. Det var ofte i samme format som hulkortene, nu kaldet records. En samling af ens records, med faste recordlængder, blev kaldt et dataset. Recordformatet og tegnsættet har påvirket stort set alt i en mainframe. Programmeringssprogene COBOL og PL1 er dannet og struktureret til at behandle records. En kodelinje i et af disse programmer er 80 karakterer. En linje på outputpapiret blev også regnet for en record, som regel på 133 karakterer.

Hulkort
Hulstrimmel
Mange andre operativsystemer brugte hulstrimmel som input, blandt andet "Regnecentralen". Her læste programmerne en karakter ad gangen i tegnsættet ASCII og "recorden" sluttede med en null-karakter (binær nul). Det gav en bedre udnyttelse af papiret end hulkortene, men en hulstrimmel kunne selvsagt ikke sorteres Hulstrimlen blev lagt på disk eller tape i samme "strimmelformat" og kaldt en fil. Karaktererne i filen læses ind i programmet i en strøm af ASCII-bytes. Det har haft ligeså stor betydning for arkitekturen for UNIX og Windows, som hulkortene har for mainframe. Programmeringssprogene, f.eks. C og Java, har karakterstrenge med ubestemt længde med en null-terminator, hvor karakterfelterne i COBOL har fast længde. Netværksprotokollen IP er streamorienteret som en fil, så man læser fra netværket ligesom man læser fra en fil. Da "records" i streamorienterede filer er null-terminerede, har filerne typisk ikke binære data. Det er til gengæld meget almindelig for mainframe records.
Disse grundlæggende historiske fakta gennemsyrer stort set alt i vore dages operativsystemer.

Hulstrimmel
Er batchprogrammer blevet umoderne?
Mainframecomputeren blev de første år kun brugt til "batchbehandling". Det var (og er stadig) særdeles populær måde at behandle data. Batchkørsler, som de normalt kaldes, er egentlig en videreførsel af hulkortbehandlingen i 50’erne, hvor man behandlede et helt parti eller bundt ("batch" på engelsk) hulkort med et program.Et godt eksempel kunne være lønbehandling:
Arbejderne på en fabrik skrev deres arbejdssedler med timer, akkorder og medarbejdernummer i hånden. Sedlerne kom ind i en såkaldt hullestue, hvor de blev indtastet til hulkort. Alle hulkortene med lønoplysningerne blev samlet i en stak og lønkørslen blev startet. Resultatet blev skrevet ud på kædeprinterer som lønsedler og lønstatistikker, og der blev dannet et dataset, der var input til bogholderikørslen senere. Indsamlingen af løninputdata sker selvfølgelig automatisk i dag, men lønkørslen er stort set den samme.
Programmeringssprogene COBOL og PL1 blev netop opfundet til batchkørsler, men er konstant blevet moderniseret. COBOL kan i dag f.eks. også bruges til objektorienteret programmering
Batch på mainframe
En batchkørsel er væsentlig forskellig fra online-programmer, som de websider, du bruger hele dagen. Inputdata til batchkørslen ligger klar til at blive behandlet, så programmerne kan potentielt bruge CPU’en 100%. Det er imidlertid ikke sikkert, at det er muligt, da I/O-kapaciteten skal kunne følge med. Derfor er der lagt store anstrengelser i at designe mainframen, så den hurtigt kan læse og skrive data til de eksterne enheder. På en mainframe er der et helt selvstændigt I/O-subsystem med egen CPU, buffere og mange kanaler til de eksterne enheder, således at I/O kan køre fuldstændig parallelt og asynkront med programmet, og der kan være flere I/O-operationer i gang samtidig.
Effektiv programmering
Der var ikke meget storage (RAM) på en computer i 60’erne - 64K, hvis den var stor. Hvordan kunne man så behandle tusindvis af lønsedler, fakturaer osv? Svaret er: planlægning og struktur. Programmøren sørgede for, at recordene i datasettene lå i den rigtige sekvens. Lønsedlerne blev sorteret i medarbejderorden ligesom medarbejderkartoteket. Lønprogrammet kunne så læse lønsedlerne og medarbejderkartoteket sekventielt igennem og skrive lønsedlerne ud. Det kræver ikke meget storage (RAM) til data og I/O er meget effektivt. God udnyttelse En mainframe kører typisk mange kørsler samtidig, for eksempel en til hver kunde eller forskellige funktioner, såsom løn, bogholderi, varelager og backup. Hvis ikke en enkelt kørsel kan bruge al CPU-kraften, fordi den skal vente på I/O, så kan en anden kørsel få glæde af den overskydende CPU-kapacitet. En mainframe kører bedst ved en CPU-benyttelse mellem 80% og 100%. Hvor godt udnytter du din PC’s eller servers CPU?
Batch i dag
Batch køres nu om dage typisk om natten, hvor der er lille on-line aktivitet. Det giver en god udnyttelse af systemet, og det er også praktisk at kunne behandle dagens input og gøre klar til næste dag.
CICS
Batch behandling er selvfølgelig ikke den eneste måde at tilgå og opdatere data på z/OS. I 1969 opfandt IBM CICS - udtales i Danmark "kiks". CICS skulle behandle og vise data på terminaler hos brugerne. Brugerne udfyldte nogle felter på deres grønne skærm, kaldet 3270-terminal, og trykkede "enter", hvorefter data fra CICS blev vist på skærmen. I Unixmiljøet sendes alle tastetryk, som f.eks. i "bash", til den centrale computer. 3270-terminalen sender kun noget ved tryk på "enter". Det gør det muligt for CICS at starte et "task" til behandlingen af dette ene "enter" og derefter glemme alt om terminalen, indtil det sender næste "enter" med data. CICS kan have 100-vis af tasks kørende samtidig og behandle millioner af tasks hver dag.Programmering
CICS-programmering er derfor væsentlig forskellig fra batch-programmering. Et CICS-program skal kun behandle et eneste "enter" fra terminalen. Den er derfor i sin natur tilstandsløs ("state-less"). Et CICS-program får, som det første, præsenteret data fra terminalen, hvorefter den behandler dem og til sidst sender svaret til terminalen og slutter. Det er lidt upraktisk i den virkelige verden at være tilstandsløs, så et CICS-program gemmer typisk oplysninger om, hvortil den kom i kommunikationen med brugeren, indtil næste gang der kommer data fra netop den terminal.
Programmeringssprogene er stadig COBOL og PL1, og de tilgår operativsystemet gennem et API kaldet "EXEC CICS", svarende til "EXEC SQL" til DB2.
Et eksempel kunne være "EXEC CICS READ FILE(filename) INTO(storage field)".
Java kom til for ca. ti år siden, og det var en stor ændring for CICS. CICS er nu også en meget effektiv Applikation Server på linje med WebSphere Application Server. Java er objektorienteret, så derfor skal man bruge nogle dedikerede Java-klasser for at gøre det, som EXEC CICS gør. Man kan selvfølgelig også lade helt være og kode sine java-programmer, som på alle andre Java Application Servere.
Hvem bruger CICS
3270-terminalerne bruges stadig som emuleringer på PC’er, men langt den største mængde af CICS-tasks behandler data fra ATM’er, Internet-transaktioner, web-services og korttransaktioner m.m. CICS bruges af stort set alle z/OS-installationer. Den har dog konkurrence fra IMS.Cics Initials Confuse Sometimes
Jeg glemte vidst at fortælle, hvad forkortelsen CICS betyder. Der har været mange gæt gennem tiderne,
så IBM lavede engang en plakat med alle tænkelige betydninger - f.eks. Can It Cook Soup.
Det rigtige svar er Customer Information Control System.
CICS udtales forskelligt på forskellige sprog. I USA udtales bogstaverne hver for sig: C-I-C-S.
På tysk hedder den SIKS. Englænderne gør som os: KIKS.
Kært barn har mange navne
VS bliver til MVS
Direkte adressering
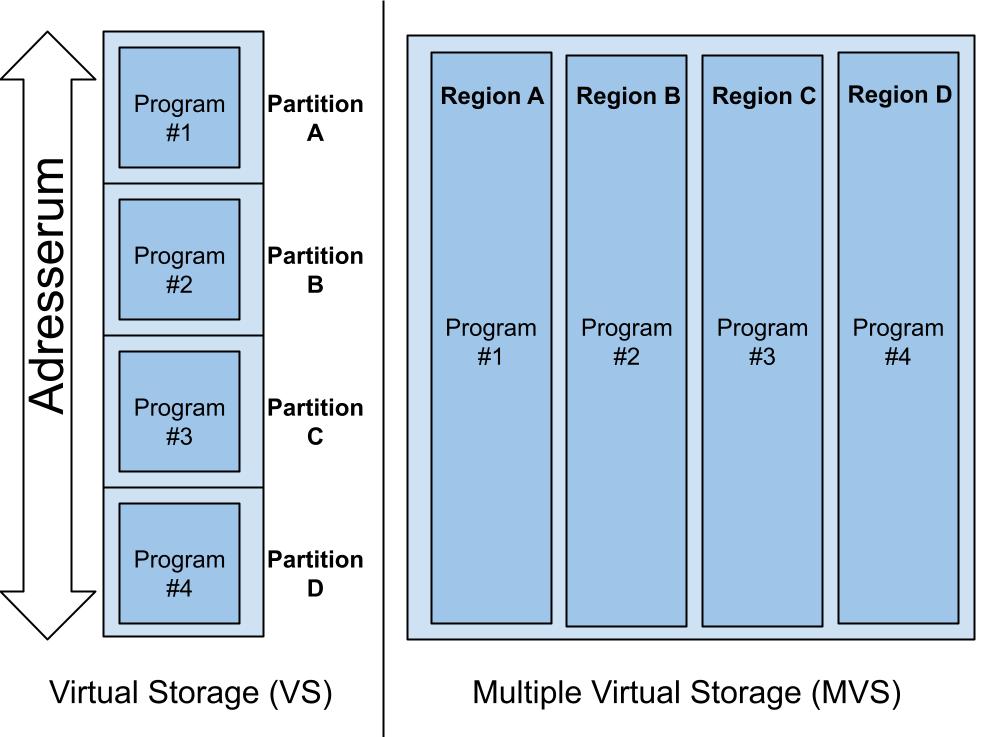
I starten allokerede programmerne i System 360 direkte i storage (RAM). Når der kørte flere samtidig kunne man risikere at de, ved et uheld, kom til at ødelægge hinandens allokerede storage. Derfor blev hvert program tildelt et unikt nummer mellem 1 og 15, en såkaldt "storage key", som så blev brugt ved allokering af storage. Programmet kunne ikke tilgå de andres storagearealer og hvis de alligevel forsøgte, blev de straks afbrudt, - et såkaldt ABEND (ABnormal END). De kørte i deres egen partition, som det blev kaldt.
Læs mere:
Virtual Storage
I 1969 kom IBM med et gennembrud i udviklingen af storageallokering og udnyttelse af indstallerede real storage (RAM). IBM viste, at Virtual Storage (VS) nu kunne lade sig gøre rent kommercielt. Der var nu et større adresserum (Address Space), med andre ord kunne et program adressere mere storage end der var installeret real storage. Det betød samtidig, at ubrugte 4K storageområder (pages) blev lagt på disk og hentet ind, når et program skulle bruge dem. Det kaldes paging og det giver en bedre udnyttelse af det installerede real storage. Endnu flere jobs kunne nu køre samtidig på mainframen.
Multiple Virtual Storage
I midten af 70’erne skete der endnu en stor ændring i storage allokering. Man fik pludselig mange VS’er, så nu kunne hvert program eller proces have adgang til hele adresserummet. Multiple Virtual Storage (MVS) var født. I princippet kunne der nu være 1000-vis af Adress Spaces ved siden af hinanden. Et Adress Space kaldes tit en Region. Det smukke ved dette design var, at nu kunne intet program adressere sig over til en andet program og de havde al den plads de kunne ønske sig. De havde hver deres lille virtuelle verden af køre i, med andre ord: De troede, de havde hele maskinen for sig selv.
Udvidelse af Adress Space (adresserummet)
Da IBM opfandt instruktionssættet til mainframen, var der ingen, der kunne forestille sig, at man nogensinde kunne få brug for at adressere mere en 16MB, dvs. 24 bits adressering. Et adresseregister er heldigvis på 32 bit, så da det blev nødvendigt, kunne IBM udvide adresserummet til 31-bit adressering, hvilket er 2GB. Den sidste bit blev brugt til at fortælle, om man køre 24 bit adressering eller 31 bit. Nu hed det MVS/XA (eXtended Architecture).
Man skal lægge mærke til, at alt, der før kørte 24-bit, stadig kunne køre på en 31-bit maskine. Uden recompilering eller nogen som helst anden ændring. Implementeringen af 64-bit adressering medførte også at navnet skiftede til z/OS, men selvfølgelig stadig således, at programmer compileret i 60’erne kunne køre upåvirket af revolutionen omkring dem.
Kontinuitet
Kan en z/OS blive syg?
Næppe, - en z/OS har et bedre immunsystem end de fleste andre operativsystemer. Det beskytter den mod især virusangreb. Forklaring følger nedenfor, men jeg advarer lige læseren mod et forhøjet nørdeniveau. Den skal nok blive sænket igen i de kommende artikler.
Program og data er adskilt
Hos andre operativsystemer kan man lægge eksekverbar kode (exe-filer) i samme folder, som der ligger datafiler. Det er pr. design ikke muligt på z/OS. Eksekverbar kode (loadmoduler), skal ligge i et bestemt formateret dataset (fil), et loadlib. Et sådant datasæt er selvfølgelig skrivebeskyttet for næsten alle.Skrivebeskyttede programmer
Det er næsten obligatorisk, at compilere og linke et program, så det kan bruges af mange processer samtidigt. Det kaldes at programmet bliver reentrant. Det betyder også, at man ikke kan ændre i programmet, - f.eks. ændre statiske variable, men mere vigtigt, programmets maskinkode kan heller ikke ændres, - hverken af programmet selv eller andre. Det er fordi programmet er hentet ind i et skrivebeskyttet område i hukommelsen, hvor alle andre programmer kan kalde og bruge det. Hvis ikke et program er reentrant, så bliver en ny kopi loaded ind i hukommelsen hver gang, det bliver refereret. Selvsagt er dette ikke godt for performance.Storagebeskyttelse
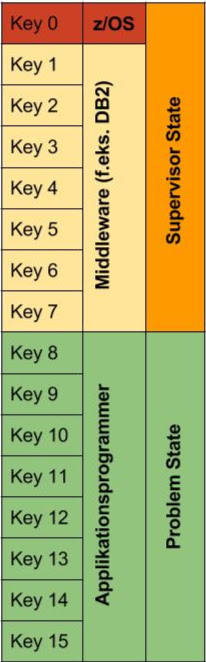
Nu vil den opmærksomme læser måske sige, at selvom programmet ikke kan ændre sin egen maskinkode, så kan den vel læse eller ændre data i f.eks. operativsystemet. Det kan den ikke, fordi her træder en anden storagebeskyttelse i funktion. Man adskiller groft sagt storage til operativsystemet og til applikationen. En slags nøglebeskyttelse (key protection). Dit program skal køre med en bestemt nøgle (key), for at få adgang til storage, som er beskyttet med samme key. z/OS opererer med 16 keys. 0 til 7 er forbeholdt operativsystemet og 8 - 16 til applikationsprogrammer, som regel bruges kun 8. Skulle et program i key 8 forsøge at ændre noget storage i key 7, så bliver det straks smidt af, hvorimod et program i key 7 kan godt ændre storage i key 8, men ikke i key 0 - 6. Det giver jo god mening, når vi tænker på, at det er operativsystemet, der leverer data til applikationsprogrammerne. Et subsystem, som f.eks. DB2, får tildelt key 7, så den er beskyttet fra applikationskoden og de andre under key 8. Key 0 er helt specielt. Programmer i key 0 har fuld adgang til alle storagearealer. Det er operativsystemets egen key. Tænk på det som en slags Super User.Beskyttelse af instruktioner
Når vi herefter taler om programmer, så vil det typisk være assemblerprogrammer. Det er de eneste, der har direkte adgang til alle instruktioner på hardwaren. Et program kan køre i enten problem state eller i supervisor state. Det første er almindelige programmer, det sidste er operativsystemprogrammer. Programmer i problem state har kun adgang til generelle instruktioner, - programmer i supervisor state kan desuden udføre privilegerede instruktioner. Det er faktisk kun en enkelt bit, der afgør om dit program kan køre supervisor state eller du må blive i problem state, sammen med resten af pøblen. Det er den såkaldte autorisationsbit. Med den sat, kan du køre autoriseret og kan selv skifte til supervisor state, hvis du skulle få lyst. Med stor magt følger et stort ansvar og kun få får den autorisation.
Autoriseret
Jeg ved udmærket godt, at nu klør det i dine fingre for at få fat i en autorisationsbit, men de ligger altså ikke og flyder på gaden. Når du compilerer og især linker dit assemblerprogram, siger du, at du gerne vil køre autoriseret og autorisationsbitten bliver sat i loadmodulet. Men det virker ikke, med mindre programmet bliver loaded fra et autoriseret loadlib. Et loadlib bliver autoriseret, hvis dets navn ligger i en slags propertyfil til z/OS. Loadlib’et er selvfølgelig beskyttet som Ford Knox og kun autoriserede personer kan lægge programmer i biblioteket.
Separation of Duty
Netop for at beskytte disse autoriserede loadlibs, kan en programmør ikke selv få lov til at lægge et program på maskinen. Det gøres af en anden person, der er uafhængig og som logger ændringerne. Det kaldes Separation of Duty.
Min egen virus
DB2
Codd & Date arbejdede igennem 70’erne hos IBM på at definere en relationsdatabase. Hvis den kunne implementeres, ville det være et gigantisk spring fremad for databaser. Der var allerede andre databasetyper, som IBMs hierarkiske database IMS/DL1. I den hierarkiske database tilpasser man accessvejene til programmerne. Den relationelle database var derimod skabt uden sammenhæng med programmerne. Det ville give en uhørt fleksibilitet, men desværre var omkostningen en meget dårlig performance.Der gik mange rygter i 70’erne om, at der snart ville komme en ny relationel databasemanager fra IBM. I 1984 kom den. Den hed DB2 og den kørte på MVS. Sammen med DB2 kom også SQL, som et programuafhængigt dataaccessprog.

Jeg citerer Frank Petersen, JN Data A/S - DB2 Customer:
Jeg kommer tilbage til data sharing i en senere artikel, som giver mulighed for 10.000+/transaktioner/sekund.
Inden et program kunne tilgå en DB2-database blev programmets SQL udtrukket i et DBRM-modul, som kunne analyseres i forhold til databasen. Analysen kaldes Static Binding og resultat af denne bind er accesvejen til databasen. Det gav god mening, at databasen ikke skal analyseres for hver transaktion. Ulempen var, hvis databasen ændrede karakter, blev transaktionerne meget langsomme. Det kunne være at en tabel gik fra at indeholde få rækker til flere millioner rækker. Det burde føre til en helt anden accesvej til data, - f.eks. brug indekser. Man måtte så Rebinde programmets DBRM. Senere versioner gjorde DB2 mere avanceret, så den kunne tillade Dynamic Binding. Et eksempel er JDBC. Første transaktion udfører en bind og accesvejen gemmes (cashes) til senere transaktioner. Det giver en meget større fleksibilitet. Lægger man et index på en tabel, så ændrer accesvejen sig ganske automatisk, hvis det altså er fordelagtig.
DB2 er i dag de facto standard for databaser på mainframe. Da Provinsbanken havde slukket den sidste NCR-computer, kørte hele den finansielle sektor på mainframe og i dag kører stort set alle mainframeinstallationer DB2.
Efter denne succes for DB2, blev der lavet DB2 til alle platforme.
MQ - Message Queueing
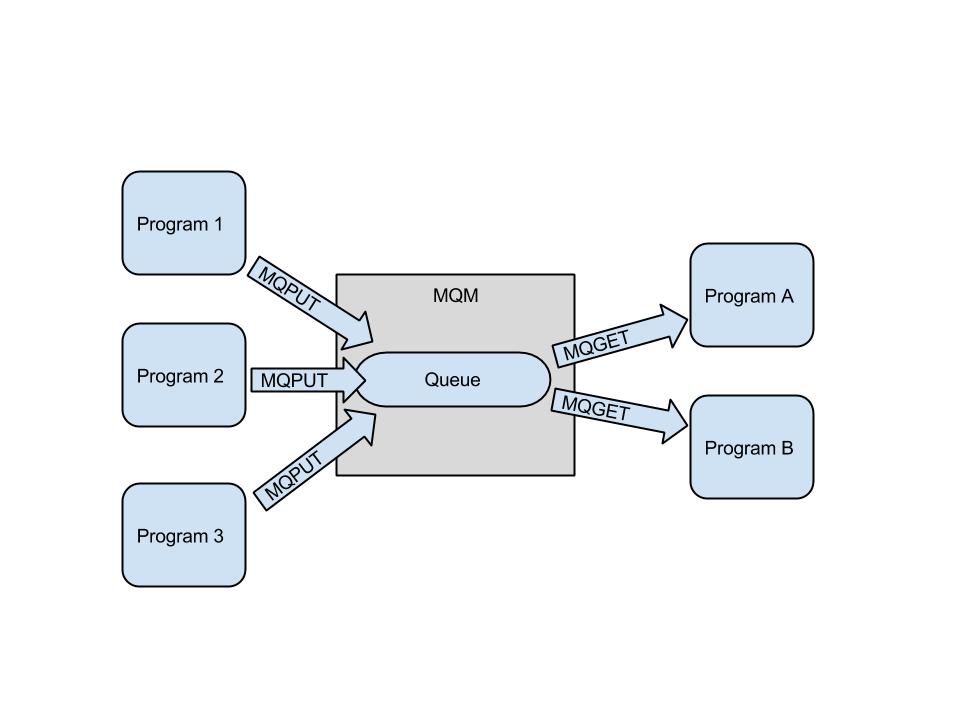
Vi er nu kommet det tredje middleware, som du helt sikkert vil møde, når du begynder at arbejde med z/OS. De to første var CICS og DB2. Denne gang er det IBM MQ. MQ står for Message Queue, og er kommunikationssoftware, som sender messages fra et program til et andet. En message er "bare" en streng af karakterer, - en record. Det specielle ved MQ er, at den sender messages asynkront. Det betyder, at så snart dit program har afleveret en message til MQ, kan det fortsætte og MQ vil så sende det frem til modtagerprogrammet. Dit program ved ikke, hvor den havner og modtageren ved ikke, hvor den kom fra. Alt er styret af MQ’s infrastruktur.
MQs infrastruktur
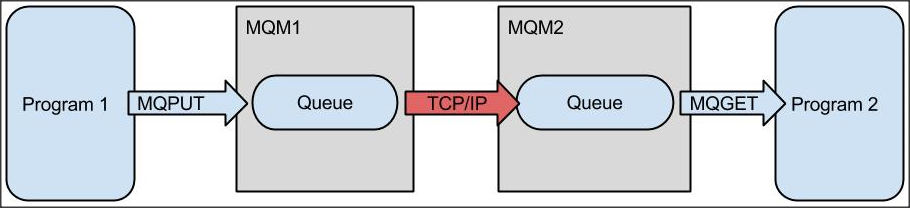
Mange programmer kan skrive i den samme kø og mange programmer kan hente messages fra samme kø. Det giver en stor grad af parallelitet. MQ-administratoren kan sætte kommunikationskanaler op mellem MQ-managers, så det bliver muligt at sende messages mellem MQ-managers og dermed mellem computere over hele verden.
Fordele
MQ har nogle helt fundamentale fordele:
- Garanteret levering af messages
- Aldrig tab af messages
- Ingen dobbeltlevering af messages
Disse tre fordele har været årsag til udbredelsen af MQ.
Local Queue
Remote Queue
Platforme
MQ blev i første omgang udviklet til z/OS, men var fra starten tænkt som et multiplatformmiddleware. Alle operativsystemer kan installere MQ og dermed sende til alle andre. Det betyder, at sender og modtager måske bruger forskellig code page. (ASCII, EBCDIC, Unicode osv.) eller kommer fra forskellige sprogområder, hvor bogstaver og tegn har forskellige placeringer i Code Page tabellen. Afsenderen angiver i sine messages, hvilket code page message er skrevet med. Modtageren har så muligheden for at konvertere til sin egen code page. Globaliseringen har vist, at det kan være af stor betydning. Lav dine messages (f. eks XML) i din code page og modtageren kan fortolke dem i sin egen code page.MQ-programmer
Jeg har lavet mange MQ-programmer gennem tiden og set endnu flere og man kan virkelig undres over, hvor mange forkerte måder, der er at kode op mod MQ på. MQ er meget nem at bruge for en programmør, men det har så den ulempe, at han/hun ikke mener, at det er nødvendigt at læse manualen eller tage et kursus. Jeg er åbenbart ikke den eneste, der er af den opfattelse. En noget frustreret MQ-specialist har lavet ti bud, som en MQ-programmør, som minimum, bør overholde. Der er lavet amendments og jeg kunne såvel også selv tilføje nogle enkelte.
Ten Commandments
- Thou shalt not use a queue as a database.
- Thou shalt backup your pagesets, filesystems, and logs.
- Thou shalt routinely apply maintenance to your IBM MQ systems.
- Thou shalt use MQCLOSE and MQDISC when terminating an application.
- Thou shalt not use MQGET with WAIT UNLIMITED without specifying MQGMO_FAIL_IF_QUIESCING.
- Thou shalt secure all client-channel connections to a queue manager.
- Thou shalt create standard naming conventions.
- Thou shalt provide systems management tools for administrators and users.
- Thou shalt not create a IBM MQ network without mapping out all connections and object relations on paper first.
- Thou shalt not attempt to apply asynchronous methods to all problems simply because IBM MQ is a wonderful product.
Reference: De ti bud
z/OS i kloster
Vi ved alle, at en computer i bund og grund er opbygget af transistorer. De kan imidlertid opbygges på to måder, bipolar eller CMOS. De bipolare kredsløb var op til starten af halvfemserne de hurtigste. I PC’er brugte man CMOS-teknologi. De udviklede mindre varme og var derfor nemmere at håndtere. Udviklingen skete på CMOS, så i halvfemserne skiftede IBM teknologi på mainframe fra bipolare kredsløb til CMOS-kredsløb. De enkelte CPU’er på hardwaren blev umiddelbart langsommere, men hver computer fik flere. Parallelitet skulle nu være svaret på hurtigere computere. Samtidig kom det nye buzz-word i branchen: 99,999% oppetid. Det gik under navnet "five nines". Man tillod dermed højst 5,2 minutters nedetid på et år. Det er uhyre svært at overholde. Den eneste måde IBM kunne opfylde disse krav var at opfinde Parallel System Complex, nu kendt som Parallel SysPlex, eller bare SysPlex. Man kan koble op til 32 uafhængige z/OS-mainframes sammen. Du kender det måske fra andre systemer som clustering eller klynge.
Uafhængighed
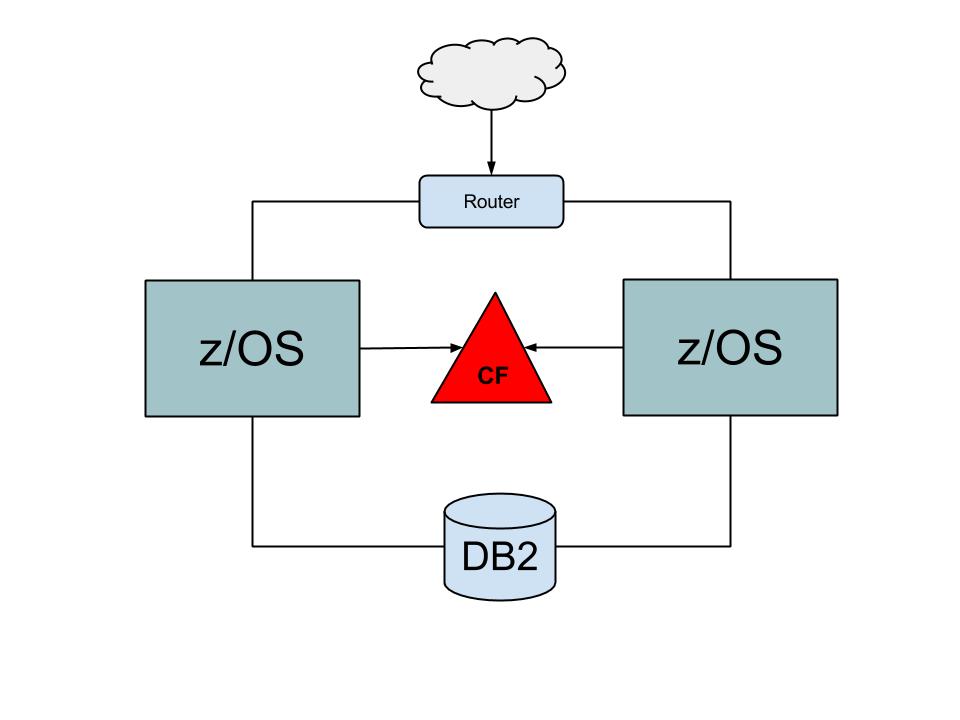
Det fungerer i bund og grund ved, at man sætter to eller flere mainframes sammen om det samme disksystem. Flere DB2’er kan tilgå de samme tabeller, selvom de kører på flere mainframes. Det ville selvfølgelig give problemer med opdateringer af samme række i en tabel i DB2, hvis ikke det var fordi, de havde et fælles sted at markere en lås på denne række. Stedet kaldes en Coubling Facility (CF). CF’en er en selvstændig z/OS, hvis eneste opgave er at styre et SysPlex. CF’en kan selvfølgelig dubleres. Man sætter typisk en avanceret netværksrouter foran et SysPlex, som kan fordele indkomne transaktioner mellem de enkelte z/OS-mainframes i et SysPlex. Skulle en enkelt z/OS i SysPlex’et falde ud, fortsætter de øvrige uanfægtet. Det giver store muligheder for ægte 24*7 tilgængelighed ved både planlagte og uplanlagte nedbrud. Nogle SysPlex’er har kørt i flere år uden nedbrud.
CMOS-kredsløb er nu langt over de tidligere bipolare kredsløb i hastighed, men selv de er nu også ved at nå deres maksimum. Selvom man kunne sætte mange hundrede CPU’er i samme mainframe, ville operativsystemet ikke kunne udnytte dem, da selve administrationen ville give et overhead. Til sidst ville tilføjelse af en enkelt CPU måske kun give en forøgelse af den samlede CPU-kraft på 10%. Det dur selvfølgelig ikke. Fordelen ved at bringe flere uafhængige mainframes sammen i et SysPlex er netop, at de er uafhængige. Det er et helt grundlæggende paradigme, at de i princippet ikke kender noget til hinanden. De ved sådan set ikke, at de tilhører en SysPlex, bortset fra at de laver DB2-lås i CF.
Ingen administration
IBM MQ, som du læste om tidligere, kan lægge en kø ud i CF. Alle MQ’er på alle z/OS’er i SysPlex’et kan nu tilgå køen, - både skrive og hente messages. Forestil dig, at samme applikation kører på alle z/OS’er i SysPlex’et og de alle henter messages fra den delte kø (Shared Queue). Her er avancerede algoritmer ikke nødvendig for at fordele messages i SysPlex’et. De henter hver næste message, når de har tid. Vi har en optimal fordeling af message og dermed fordeling af CPU-forbrug. Der ingen overhead til administration. MQ sørger for at en message kun bliver hentet en gang og at alle bliver hentet.
Referencer
Parallel System Complex
z/OS og Unix
Jeg ved godt, at du, som studerende, elsker din Unix. Du kan lave alle mulige manipuleringer med data og du har måske endda skrevet en kerne eller en compiler. Alle IT-studerende kender Unix. Der er faktisk også en del af z/OS, der er Unix. Det er ikke lavet for din skyld, - ikke direkte, i hvert fald. Mange professionelle IT-uddannede, laver systemer til Unix og måske især til den "åbne verden". IBM vil selvfølgelig også gerne kunne tilbyde sine z/OS-kunder systemer fra denne "åbne verden" på z/OS.Derfor har z/OS også en Unix, - ikke en virtuel Unix, der kører under z/OS, men en Unix sammen med z/OS. De kan dele alle ressourcer. Jeg synes, at særlig smukke ved dette design er, at du kan udnytte begge systemers fordele, - f.eks. kan du køre Java som batchjobs eller Java i CICS.
Filsystemer
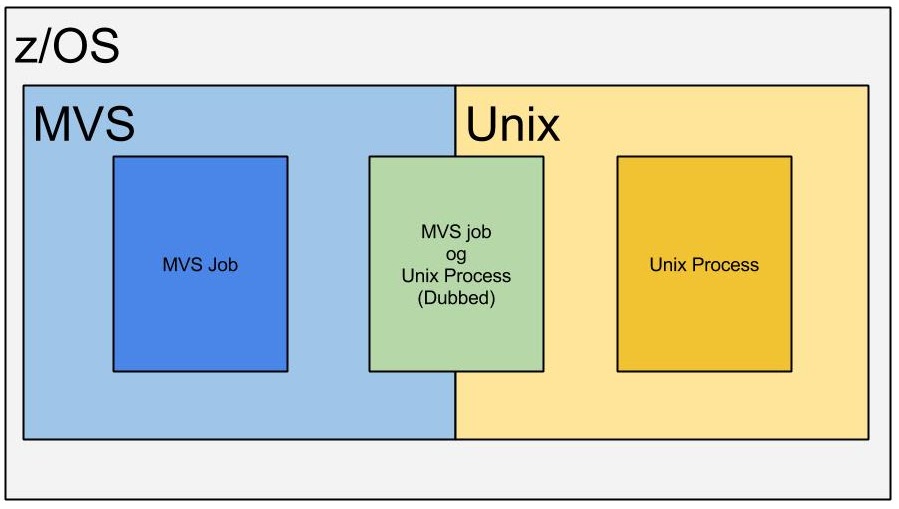
Herefter vil jeg bruge ordet "MVS" om traditionel z/OS og z/OS, når jeg refererer til både MVS og Unix En MVS har et "filsystem" uden hierarki, som Unix. Hver "fil" kaldes et dataset. Den er præformateret til f.eks. records på 80 bytes. Unix’es filsystem er streamorienteret, hvor records er adskilt med CR/LF. Derfor er filsystemerne adskilt, men hvert filsystem kan faktisk tilgås af både MVS og Unix.
Processer
Når du starter et helt almindeligt MVS-job, kender det intet til Unix-delen af z/OS. Men det kan det komme til. Hvis det begynder at referere til Unix-services bliver det "dubbed" og "undubbed", når det stopper. Det betyder, at et dubbed address space bliver kendt i Unix, som en process. Før det kendte Unix intet til det. Som du nok kan regne ud, så er begge "operativsystemer" knyttet meget tæt sammen. Så tæt, at det faktisk er samme OS. Navnene de bruger, er bare forskellige. F.eks.
- Address Space = Process
- Task = Thread
Programmer
Unix på z/OS har gjort det muligt at flytte traditionelle Unix-produkter til z/OS, - især Java. De fleste af disse produkter er skrevet i C, men da instruktionssættet på System z slet ikke er det samme, som på andre platforme, så er det ikke source-kompatibelt. Karaktersættet er EBCDIC og floating-point og integers er forskellige fra flere andre platforme. Tager man højde for disse forskelligheder, så kan man flytte sin C-kode til Unix på z/OS.
Shells
Du kan logge på z/OS og køre Unix (næsten), som du er vant til. Du kan lave avancerede scripts og editere programmer, som du plejer, men du kan også gøre det mere på z/OS-måden. Du kan udvikle, compilere og teste C- og Javaprogrammer, men det vil jeg komme nærmere ind på, i en senere artikel om udviklingsmiljøer på z/OS.
MVS og Unix er ét operativsystem.
Reference:

z/OS i netværk
System Network Architecture (SNA)
IBM definerede i slutningen af 70’erne en ny netværksprotokol, som skulle blive de facto standard i mange år fremover. System Network Architecture, eller bare SNA. Det var meget avanceret og sikrede mod tab af data. SNA var lagdelt som OSI-modellen. Mainframen var på det tidspunkt stort set den eneste kommercielle computer, så det var helt naturligt og nødvendigt at definere den som midtpunktet i netværket. Der hvor data endte eller kom fra. SNA kunne håndtere titusindvis af "dumme" terminaler. Terminalerne blev delt op efter, hvad de kunne - såkaldte Logical Units, LU’er. LU1 var printere og LU2 var skærmterminaler osv. I midten af 80’erne blev det moderne at lade programmer kommunikere med hinanden med protokollen LU6.2. Den er uhyre kompliceret, med parallelle sessions og indbygget 2-phase commit. Og så er den meget stabil
Internet Protocol
I midten af halvfemserne bød TCP/IP sig til og IBM måtte også understøtte denne protokol, selvom den, med rette, blev anset for en ustabil og usikker protokol. I dag er alt næsten TCP/IP. Hvorfor blev TCP/IP foretrukket fremfor den meget sikrere SNA? En enkelt ting gjorde udslaget. Alle forbindelser i SNA skulle defineres i den centrale router, NCP og VTAM. Det var uhyre sikkert, men kunne jo slet ikke konkurrere med TCP/IP’s dynamiske routning - alle til alle kommunikation. SNA bruges stadig, men som regel "kun" som et lag over UDP/IP eller TCP/IP, som står for al transmission.
TCP/IP
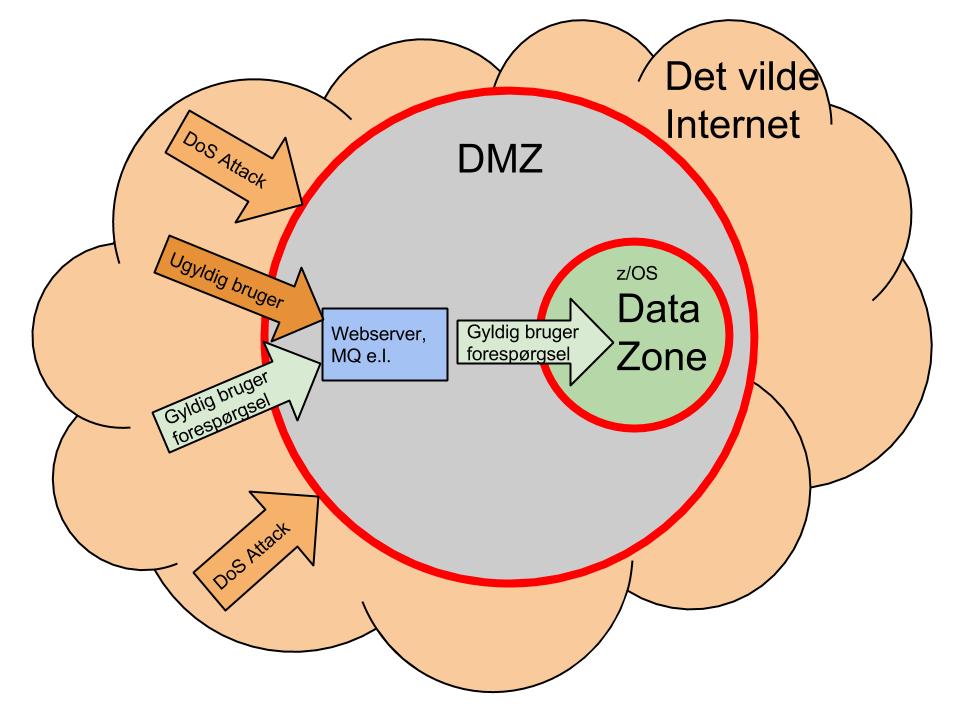
Overgangen til TCP/IP kom til at betyde en meget stor ændring for datacentrene. Sikkerheden mod misbrug var i SNA sikret ved, at parterne skulle definere hinanden, og så kunne man derudover lægge kryptering over. Efter indførelsen af TCP/IP var der pludselig ingen definitioner længere, alle kunne kommunikere med mainframen. Desværre også nogle, som havde mindre lødige hensigter. Pludselig lærte vi om ord som Deniale of Service Attacks, Hackere osv. Vi blev nødt til at definere Firewalls og DeMiliterized Zones (DMZ), for at undgå kompromittering af data og programmer.
Beskyttelse af data
Alle mainframeinstallationer med konfidentielle data har i dag defineret en DMZ. Man har således defineret to firewalls, som alle skal igennem, inden de kan se eller opdatere data på mainframe. Uden for den første firewall er der vild anarki, altså Internettet. ønsker man kontakt til mainframe applikationer, skal man således igennem den første firewall, som bl.a. sorterer DoS-attacks fra. Vel inde i den demilitariserede zone, står en webserver, MQ eller en anden formidler. Ugyldige brugere bliver her sorteret fra. Formidleren sender forespørgslen videre gennem den næste firewall til DB2. Al kommunikation bliver logget, så man kan finde tilbage til evt. angribere. På en måde er vi slået tilbage til start. I SNA skulle vi definere, hvem der måtte kommunikere med mainframen - nu skal vi definere, hvem der IKKE må.
Læs mere:
Programudvikling
Der er flere måder at udvikle programmer på til z/OS. Jeg fortæller om dem hver især. Jeg starter med den mest traditionelle, TSO/ISPF. "Time Sharing Option / Interactive System Productivity Facility"
TSO/ISPF
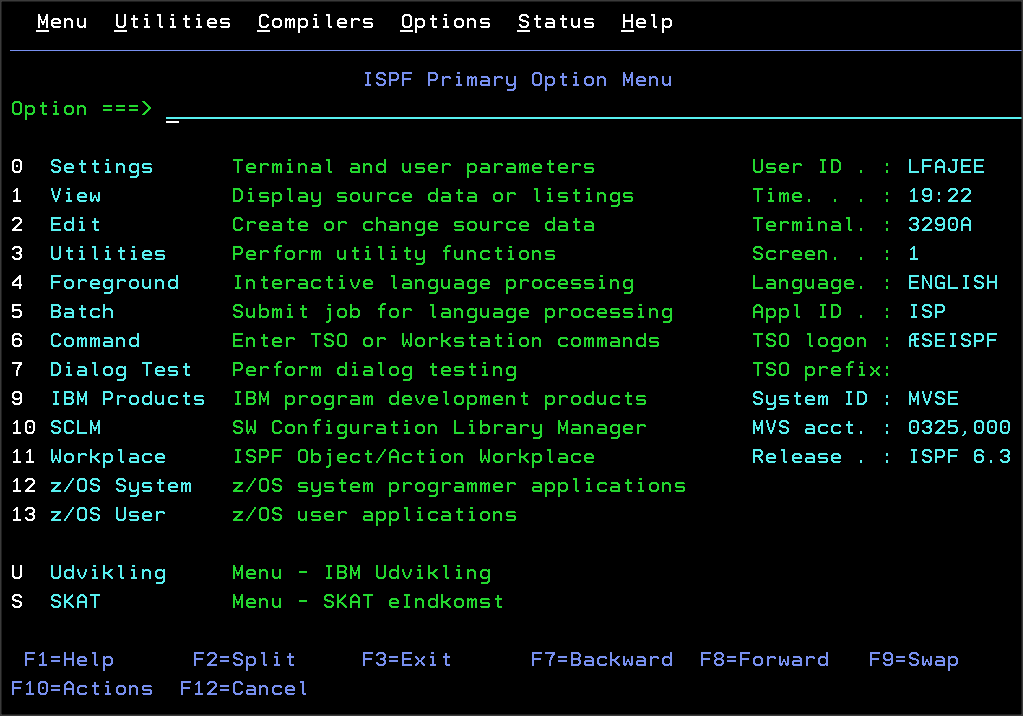
TSO er et online-system, hvor hver bruger har deres region / Address Space. TSO kan sammenlignes lidt med en Telnet-session, hvor man kan taste linjekommandoer ind. Det bruger ingen, for der er lagt en lag over, som hedder ISPF. Det er et menudrevet udviklingssystem, hvor du kan kode programmer, teste dem og manipulere med dine data osv. Brugergrænsefladen er baseret på 3270. Det forskrækker desværre mange nyuddannede, som har været vant til vinduebaseret tilgang til udviklingsværktøjerne under uddannelsen. Nogle kalder det lidt uretfærdigt "det sorte hul". Det er vel ikke mere sort end en DOS-prompt eller Telnet-session, men TSO/ISPF er betydelig mere sofistikeret.
Billedet viser et eksempel på et COBOL-program, som skal editeres. ISPF kan sætte farver på, så det bliver mere læseværdigt.
Jeg vil ikke forklare alle editeringskommandoer, men derimod henvise til Youtube Der er selvfølgelig mange flere end de viste kommandoer, men det vil give dig en ide om, hvad der er muligt.
Skrædersy din ISPF
Der følger en masse paneler/skærmbilleder med installationen af ISPF, men du kan udvide med dine egne paneler. Der findes et fortolkningssprog kaldet CLIST, som du skal bruge til det. Du kan også vælge programmeringssproget REXX. Derudover er det muligt at kalde almindelige COBOL- eller PL1-programmer fra CLIST, så du kan sådan set kode hele applikationer under TSO/ISPF. Det er nu ikke så almindeligt.
3270 - Personal Communication
Tidligere var 3270 en fysisk skærm, sort med grønne bogstaver. Derfor bliver den også en gang imellem kaldt for "green screen". I dag er det en emulator på din PC, der hedder Personal Communication. Det er typisk 80 karakterer på 24 linjer. Nu også med farver. Der er ingen grafiske vinduer, kun karakterer, så svartiden er meget hurtig, - langt under et sekund.
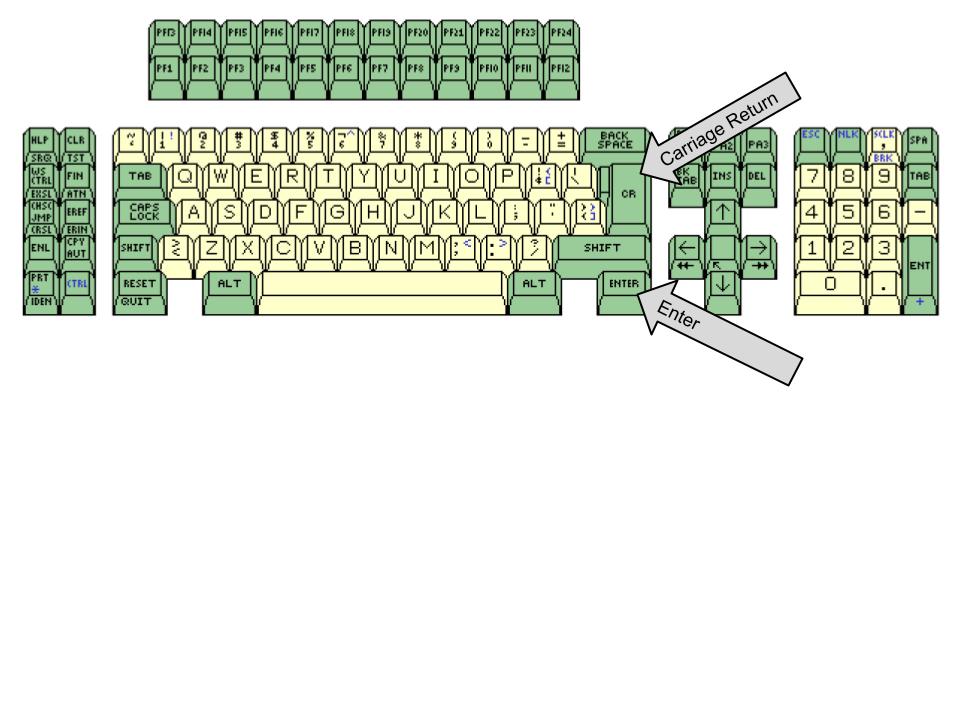
Tastatur
Der kom et andet tastatur med 3270-emuleringen på en PC. Nu skulle vi bruge Ctrl som Enter. Carriage Return gør, hvad navnet antyder, nemlig flytte cursoren til første karakter på næste linje.Unix-konsol
Da Unix kom til z/OS, skulle der også være en Unix-konsol for at blive godkendt som en ægte Unix efter POSIX-standard. Den er bygget over TSO på 3270 og kaldes OMVS (Open MVS). Det er her, man virkelig kan se forskellen på TTY-terminaler og 3270-terminaler. Hver tast på TTY-tastaturet bliver sendt til computeren, så her er det f.eks. muligt at lave code completion, hvorimod på den recordorienterede 3270-terminal, bliver der først sendt noget til computeren ved Enter (ikke CR!!). Du kan dog bruge wildcard, dvs. taste første del af f.eks. et stinavn og afslutte med *. Det svarer til at taste => (tab) på en TTY-terminal.
Rational Developer for z - RDz
Jeg håber ikke, du blev alt for forskrækket over TSO/ISPF. Den er faktisk meget populær blandt erfarne z/OS-programmører. Der er selvfølgelig også en mere "moderne" tilgang til programmering, nemlig Rational Developer for z (RDz). Det er et Eclipsbaseret udviklingsværktøj, som har inkluderet alt hvad ISPF kan og lidt til.
Intergrated Development Environment (IDE)
Eclipse er Open Source og jeg er selv meget begejstret for det til udvikling af Java. I RDz kan du desuden udvikle programmer i de traditionelle programsprog, som COBOL og PL1, men nu med de editeringskommandoer og code completion, som du er vant til. Der er selvfølgelig øjeblikkelig syntax-check, mens du koder, men derudover kan du "compilere" i RDz, så alle compileringsfejl er fjernet inden den "rigtige" compilering på z/OS. Så bliver din source flyttet op på z/OS og compileret der. Selvom dit program skal køre på z/OS, har du stadig den sædvanlige Eclipse-debugger, hvor du kan lave pause og single step i COBOL-sourcen fra din lokale RDz. Du kan følge dine testjobs på z/OS, ligesom du kan i ISPF og du kan se alle z/OS-dataset, som filer i en træstruktur. RDz kombinerer det bedste fra de to verdener, når du skal udvikle dine programmer.
Kodestandarder
Langt de fleste z/OS-installationer har en kodestandard, som alle udviklere skal overholde. Det kan måske føles lidt af en spændetrøje på dig og dine programmeringsevner, men du er ikke den eneste programmør på z/OS. Du har måske 1000 kollegaer, hvis det er en stor installation. Det skal derfor være muligt at flytte programmører mellem systemer. En kodestandard er derfor en stor hjælp til at forstå programmerne i et nyt system. Derudover kan en kodestandard forhindre fejl. RDz har derfor en mulighed for at tvinge en bestemt kodestandard igennem.
Software Configuration Management (SCM)
Alle installationer har selvfølgelig et system til at gemme versioner af deres sourcekode. IBM tilbyder Radional Team Concert (RTC) som et integreret SCM i RDz. Der findes mange andre SCM fra andre leverandører. Endevor fra Computer Associates (CA) er meget populært.Du kan selv udvide RDz med "plug-ins". CA har f.eks. lavet en plug-in, for at integrere Endevor i RDz. Så der er sådan set uendelige muligheder i RDz.
Links:
TSO/ISPF skærmbillede
Tastetur til 3270-skærm
Hybrid z
I alle de forrige artikler har jeg talt om z/OS på System z. System z hardwaren er lavet i tæt samarbejde med udviklerne af z/OS, men der er opstået nogle hybrider.
z/OS på Linux
System z hardwaren og operativsystemet z/OS hænger uløselig sammen, - eller gør de? IBM tilbyder nu et z/OS-testsystem, som kan startes på din labtop eller server: Rational Developer & Test (RD&T). Til tider også kendt som zPersonal Development Tool (zPDT). Det er en fuld z/OS, som kan køre under Redhat eller Suse Linux. Det er meningen, at en udviklingsgruppe kan få deres helt egen z/OS at køre udvikling og test på. De behøver derfor ikke at have fælles data med andre grupper. De styrer deres egen DB2, WebSphere osv. Du kan køre din RDz mod den, akkurat som på den "rigtige" z/OS. Man flytter altså CPU-forbrug fra System z hardwaren til Intel-CPU, som er billigere. Det er muligt at have op til 20 brugere kørende samtidig på z/OS på Intel, med de nuværende CPU-hastigheder.
Linux på System z
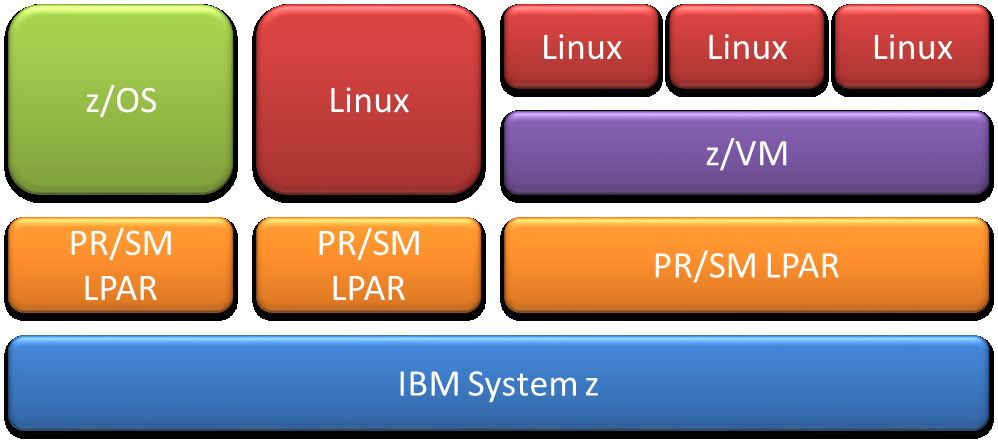
z/OS er ét af flere operativsystemer på System z hardware. Nu kan du også køre z/Linux på System z. Ikke bare én z/Linux, men hundredvis. Man starter en Virtual Machine på System z (z/VM) og derefter starter man en z/Linux på få sekunder.
System z hardware kan deles op i virtuelle System z kaldet PR/SM LPAR, i daglig tale bare LPAR (udtales el-pahr), de gule på tegningen. Tegningen viser én fysisk System z og tre logiske System z. I hver af disse kan man starte en z/OS, en z/Linux og en z/VM. I z/VM starter man så alle sine z/Linux’er. Det er ikke særlig almindelig af starte en z/Linux direkte i en LPAR. Så får man ikke fuld udbytte af sin System z.
Du husker måske, jeg skrev om zIIP-CPU’er til Java. Der er også lavet specielle CPU’er til z/Linux kaldet Intergrated Facility for Linux (IFL). Det flytter CPU-forbruget væk fra det normale arbejde (workload).
Når du logger på en z/Linux, så kan du overhovedet ikke fornemme, at du kører på System z, - måske bortset fra hastigheden. Den er lynende hurtig. En af årsagerne til det er, at en almindelig Linux ikke er særlig god til I/O. Den har kun én kanal ud til disken og CPU’en skal styre I/O. En z/Linux beder z/VM om I/O og den sørger for det vha. System z’s I/O-subsystem, der har dedikerede CPU’er til I/O.
The sky is the limit
Du kan formentlig se af det foregående afsnit, at z/Linux passer som fod i hose med Cloud. Du beder din Cloududbyder, som kører System z, om en Linux. Efter 5 minutter har du det. Det er Infrastructure as a Service (IaaS), det nederste lag i Cloud lagene. Næste lag er Platform as a Service (PaaS), hvor du får database, webserver osv. Det kan du jo lige så godt få klaret samtidig. Inden du ser dig om, har du et datacenter oppe i skyen på System z.
System z, med z/OS og z/Linux er fundamentet for det fremtidige datacenter, hvor z/OS gør det tunge arbejde med mange forskellige typer workload og z/Linux de mindre og mere ensartede workload.
Det var det sidste kapitel om z/OS for IT-studerende og andre interesserede.
Links: